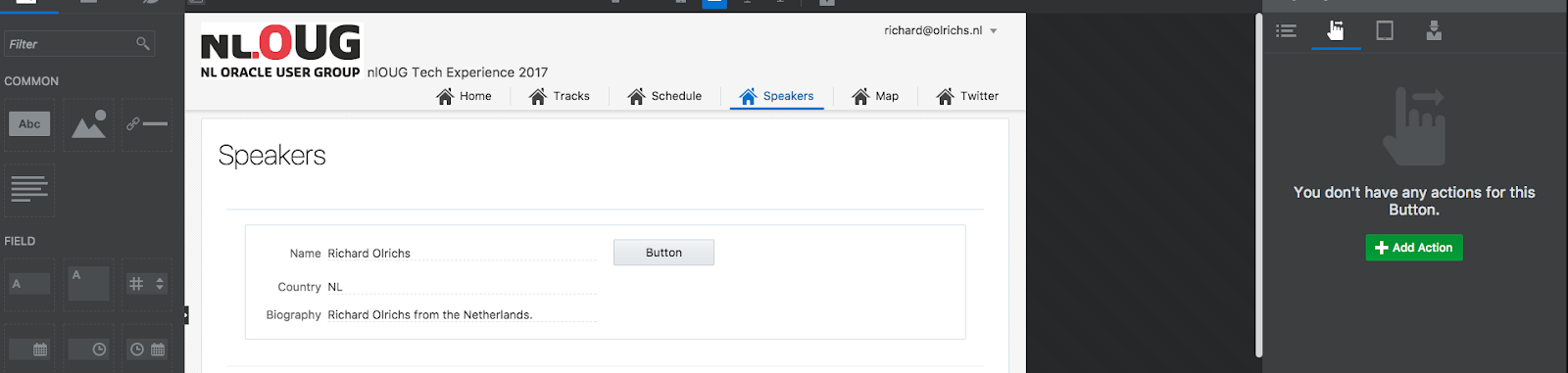
As we are very optimistic developer we started out with modeling and testing the happy flow of our Jarvis pizzeria. But as experience learns it is the big bad world that obliges us to deal with both expected and unexpected failures. This blog post we will look into the handling of SOAP faults that PCS has to offer out-of-the-box.
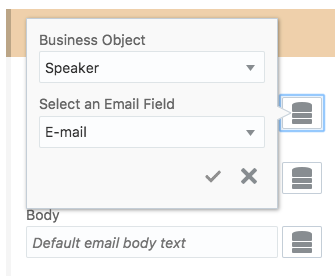
As a starting point we have created a basic process with one service call:

This SOAP Fault service is connected to mockable.io service that is configured to throw back a remote fault, i.e. the invoked service endpoint cannot be reached. Let’s deploy the process, start an instance and see in the workspace what has happened.
Note: to use the OOTB error handling leave the fault policy checkbox marked during deployment:
The graphical view shows that that the process, as expected, ran into a faulted state:

Luckily for us the engine indicated the SOAP fault as “Faulted recoverable”:

First take a look at the tree structure of the process:

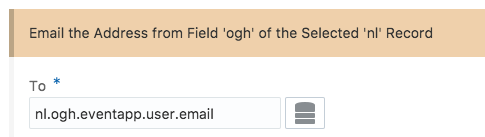
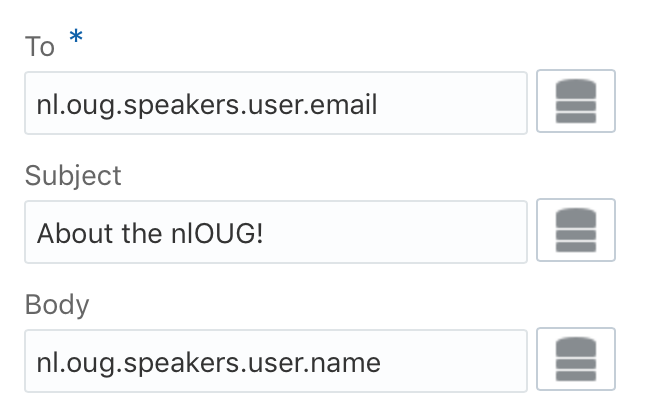
The “Instance has started the activity” shows the following request message:

All the “Instance error” show the following message:

The service has been called three consecutive times with intermediate breaks of 5 and 10 seconds respectively. The process now can be fixed with the buttons that have been discussed in a previous blog post.

Now lets deploy the exact same process but without the fault policies.
Running the process show the exact same graphical view as the one above:

However, the details section of the failure shows different data:

Note that the Status is different, without the fault policies the process is in an exception state.
Looking at the tree structure of the process we see the following:

Does this mean the process is dead right now? Well yes, more or less it is. We have two options to choose from:

Both of these options won’t bring back this process instance back to life.
The handling of SOAP faults within PCS is extremely powerful, given that you have turned on the fault policies. When the process encounters a runtime error it automatically tries to recover the fault while at the same time there is an extensive set of tools at one’s disposal to get the instance recovered. One can simply retry the service call, change instance variables, simply continue or skip the faulted activity or suspend the instance temporarily. Be aware that these powerful tools can also work adversely when using them wrong. But as always...with great power comes great responsibility.
Are there any scenarios conceivable where a developer should turn off the fault policies? The disadvantage of turning on fault-policies is that the fault policies are turned on for the entire application. If one - for whatever reason - wants to build a proprietary error handling framework than this feature should be turned off. Maybe we can see in the nearby future an opportunity to configure the fault policies in a more fine grained manner, to make this feature more powerful. Then again, compared to the on-premises error handling we’d have to say that this is a big leap forward again!